Research Projects

Text Stylization
GAN-based Text Stylization
 This work presents a novel style transfer framework for rendering artistic text from a source style image in a scale-controllable manner. It allows users to adjust the stylistic degree of the glyph (i.e. deformation degree) in a continuous and real-time way, and therefore to select the artistic text that is most ideal for both legibility and style consistency.
This work presents a novel style transfer framework for rendering artistic text from a source style image in a scale-controllable manner. It allows users to adjust the stylistic degree of the glyph (i.e. deformation degree) in a continuous and real-time way, and therefore to select the artistic text that is most ideal for both legibility and style consistency.
 In this journal version, we expand our model to dynamic text style transfer by establishing spatial-temporal structural mappings within consecutive frames. Our improved model can animate a static text image based on a reference style video, which is less explored in video style transfer, but is of great application value in digital graphic design such as website design and gif generation.
In this journal version, we expand our model to dynamic text style transfer by establishing spatial-temporal structural mappings within consecutive frames. Our improved model can animate a static text image based on a reference style video, which is less explored in video style transfer, but is of great application value in digital graphic design such as website design and gif generation.

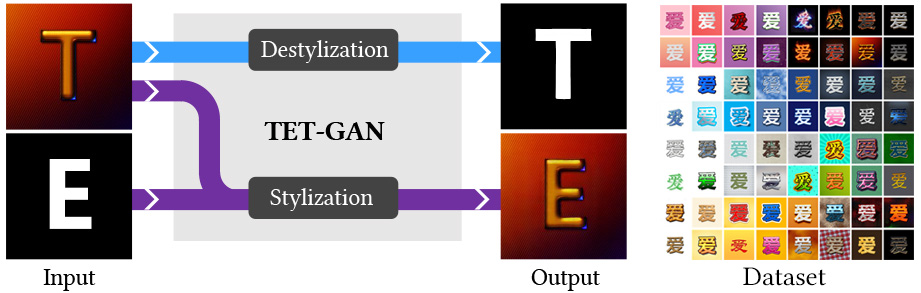 This work presents a novel Texture Effects Transfer GAN (TET-GAN), which are trained to disentangle content and style features of text effects images to accomplish both the objective of style transfer and style removal. To support the training of our network, we propose a new text effects dataset with as much as 64 professionally designed styles on 837 characters.
This work presents a novel Texture Effects Transfer GAN (TET-GAN), which are trained to disentangle content and style features of text effects images to accomplish both the objective of style transfer and style removal. To support the training of our network, we propose a new text effects dataset with as much as 64 professionally designed styles on 837 characters.
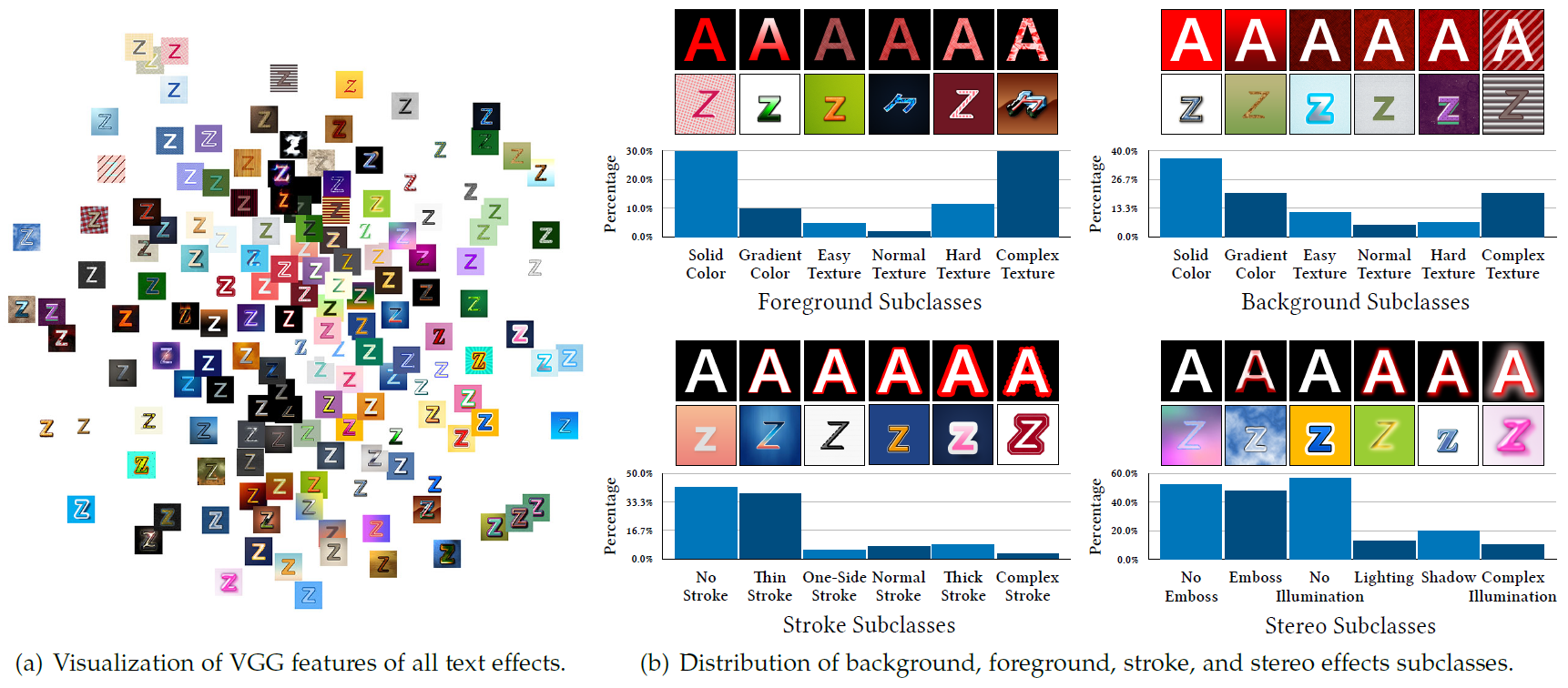 In this journal version, we focus on the construction and analysis of the new large-scale dataset TE141K with 141,081 content/style image pairs, and conducted more comprehensive experiments for model benchmarking. In addition, we expand our model to joint font style and text effect transfer and semisupervised text effect transfer
In this journal version, we focus on the construction and analysis of the new large-scale dataset TE141K with 141,081 content/style image pairs, and conducted more comprehensive experiments for model benchmarking. In addition, we expand our model to joint font style and text effect transfer and semisupervised text effect transfer

Patch-Match-based Text Stylization

 This work explores a challenging unsupervised text stylization problem, only with a text image and an arbitrary style image as input. Furthermore, we investigate the combination of stylized shapes (text, symbols, icons) and background images to create professional looking artwork.
This work explores a challenging unsupervised text stylization problem, only with a text image and an arbitrary style image as input. Furthermore, we investigate the combination of stylized shapes (text, symbols, icons) and background images to create professional looking artwork.
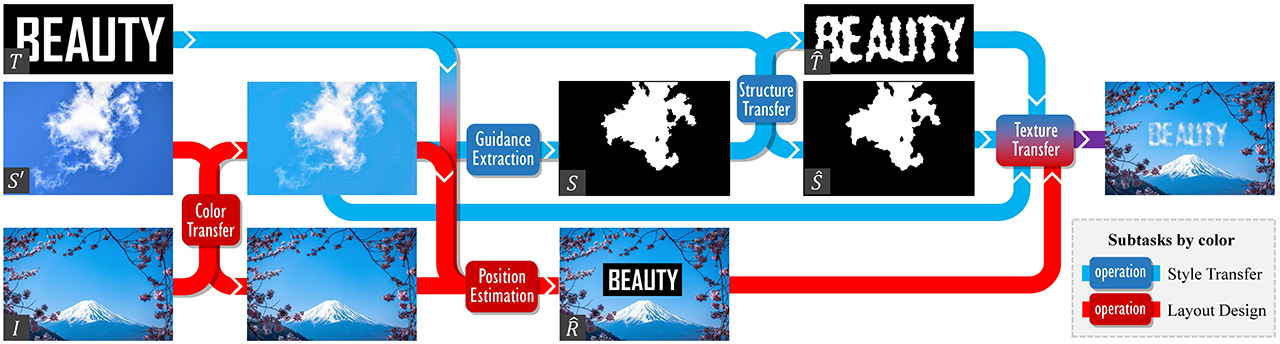 In this journal version, we further consider the rotations and scales of text, investigate the placement of each individual character rather than considering them as a whole to enhance the design flexibility, the computational complexity, and extend our method to structure-guided image inpainting.
In this journal version, we further consider the rotations and scales of text, investigate the placement of each individual character rather than considering them as a whole to enhance the design flexibility, the computational complexity, and extend our method to structure-guided image inpainting.

 This work explores the problem of generating fantastic special-effects for the typography. Our key idea is to exploit the analytics on the high regularity of the texture spatial distribution for text effects to guide the synthesis process.
This work explores the problem of generating fantastic special-effects for the typography. Our key idea is to exploit the analytics on the high regularity of the texture spatial distribution for text effects to guide the synthesis process.
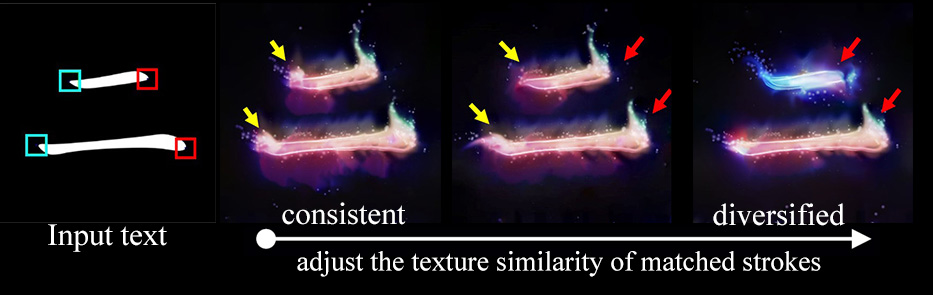 In this journal version, we introduce a new stroke term to adjust the texture similarity of matched strokes, conduct a user study and a running time comparison for quantitative evaluations, and apply our method to more general stroke-based graphics.
In this journal version, we introduce a new stroke term to adjust the texture similarity of matched strokes, conduct a user study and a running time comparison for quantitative evaluations, and apply our method to more general stroke-based graphics.

Human-Oriented Editing
Face Stylization and Editing
 This work presents a novel VToonify framework that can synthesize high-resolution stylized videos from a low-resolution input. VToonify precisely pastiches the facial structure style of style collections. Within each style collection, fine-level style transfer in terms of both structure style and color style is supported by specifying a reference style image. Besides style types, our framework further supports the adjustment of style degrees.
This work presents a novel VToonify framework that can synthesize high-resolution stylized videos from a low-resolution input. VToonify precisely pastiches the facial structure style of style collections. Within each style collection, fine-level style transfer in terms of both structure style and color style is supported by specifying a reference style image. Besides style types, our framework further supports the adjustment of style degrees.
 This work presents a novel DualStyleGAN for exemplar-based high-resolution (1024*1024) portrait style transfer. DualStyleGAN offers high-quality and high-resolution pastiches and provides flexible and diverse control over both color styles and complicated structural styles
This work presents a novel DualStyleGAN for exemplar-based high-resolution (1024*1024) portrait style transfer. DualStyleGAN offers high-quality and high-resolution pastiches and provides flexible and diverse control over both color styles and complicated structural styles
 This work presents DeepPS that allows users to synthesize and edit photos based on hand-drawn sketches. DeepPS works robustly on various sketches by setting refinement level l adaptive to the quality of the input sketches, i.e., higher l for poorer sketches, thus tolerating the drawing errors and achieving the controllability on sketch faithfulness.
This work presents DeepPS that allows users to synthesize and edit photos based on hand-drawn sketches. DeepPS works robustly on various sketches by setting refinement level l adaptive to the quality of the input sketches, i.e., higher l for poorer sketches, thus tolerating the drawing errors and achieving the controllability on sketch faithfulness.
 In this journal version, we explore more advanced user controllability on facial attribute editing and spatially non-uniform refinement. The former supplements the controllability over features that cannot be captured by the sketches such as the color information. The latter enables users to conveniently globally refine the rough sketches while locally preserving important structural details.
In this journal version, we explore more advanced user controllability on facial attribute editing and spatially non-uniform refinement. The former supplements the controllability over features that cannot be captured by the sketches such as the color information. The latter enables users to conveniently globally refine the rough sketches while locally preserving important structural details.
Face-Related Image Enhancement

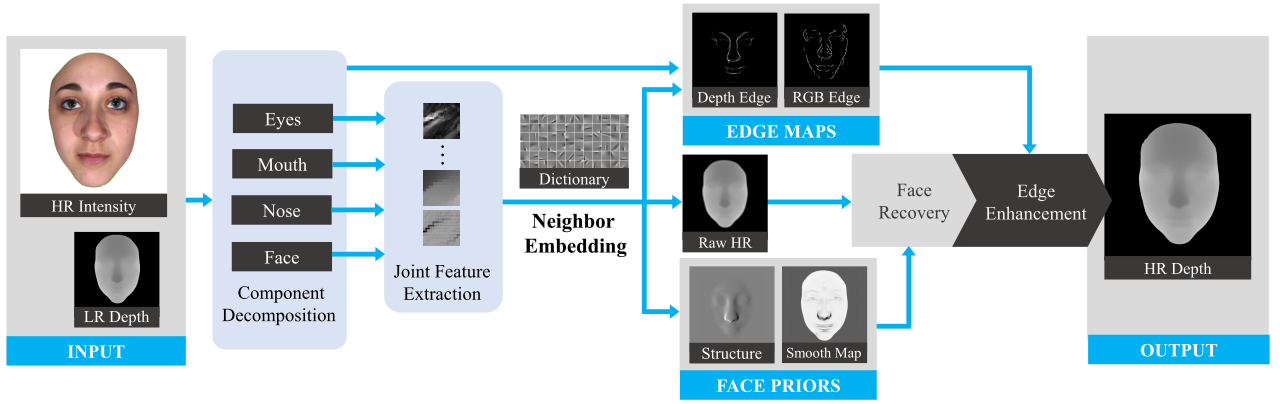 In this paper, we present a novel method to super-solve and recover the facial depth map nicely. The key idea of our approach is to exploit the exemplar-based method to obtain the reliable face priors from high quality facial depth map to further improve the depth image.
In this paper, we present a novel method to super-solve and recover the facial depth map nicely. The key idea of our approach is to exploit the exemplar-based method to obtain the reliable face priors from high quality facial depth map to further improve the depth image.

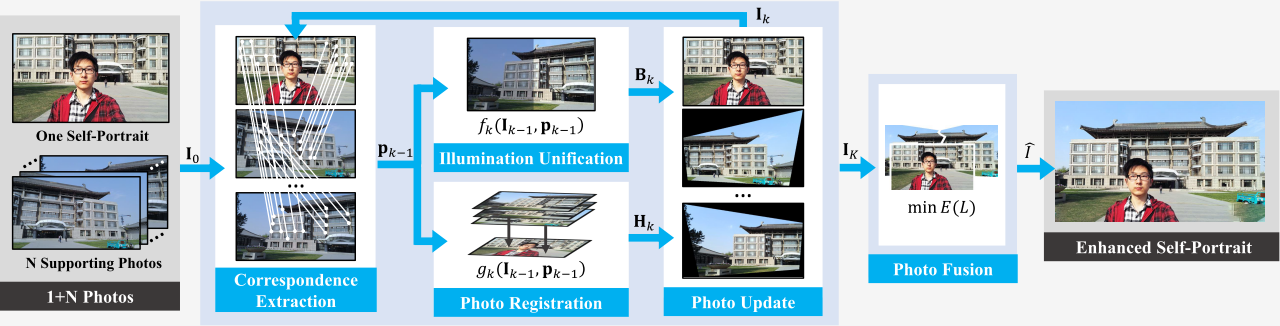 This work presents a novel cascaded framework to solve a self-portrait enhancement problem we call ''1+N'' problem, in which a self-portrait is enhanced with the help of N supporting photos that share the same scene and similar shooting time.
This work presents a novel cascaded framework to solve a self-portrait enhancement problem we call ''1+N'' problem, in which a self-portrait is enhanced with the help of N supporting photos that share the same scene and similar shooting time.
Deep Fashion

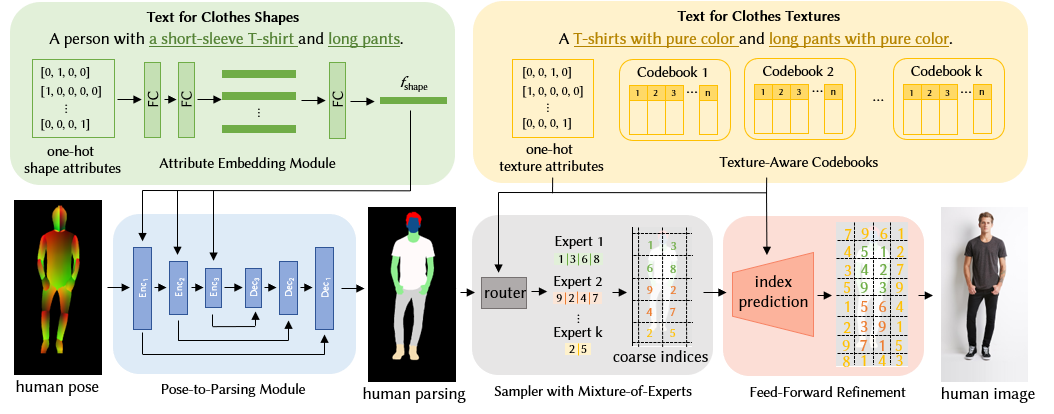 In this work, we proposed the Text2Human framework for textdriven controllable human generation in two stages: pose-to-parsing and parsing-to-human. The first stage synthesizes the human parsing masks based on required clothes shapes. In the second stage, we propose a hierarchical VQVAE with texture-aware codebooks to capture the rich multi-scale representations for diverse clothes textures, and then propose a sampler with mixture-of-experts to sample desired human images conditioned on the texts describing the textures.
In this work, we proposed the Text2Human framework for textdriven controllable human generation in two stages: pose-to-parsing and parsing-to-human. The first stage synthesizes the human parsing masks based on required clothes shapes. In the second stage, we propose a hierarchical VQVAE with texture-aware codebooks to capture the rich multi-scale representations for diverse clothes textures, and then propose a sampler with mixture-of-experts to sample desired human images conditioned on the texts describing the textures.

Image/Video Translation
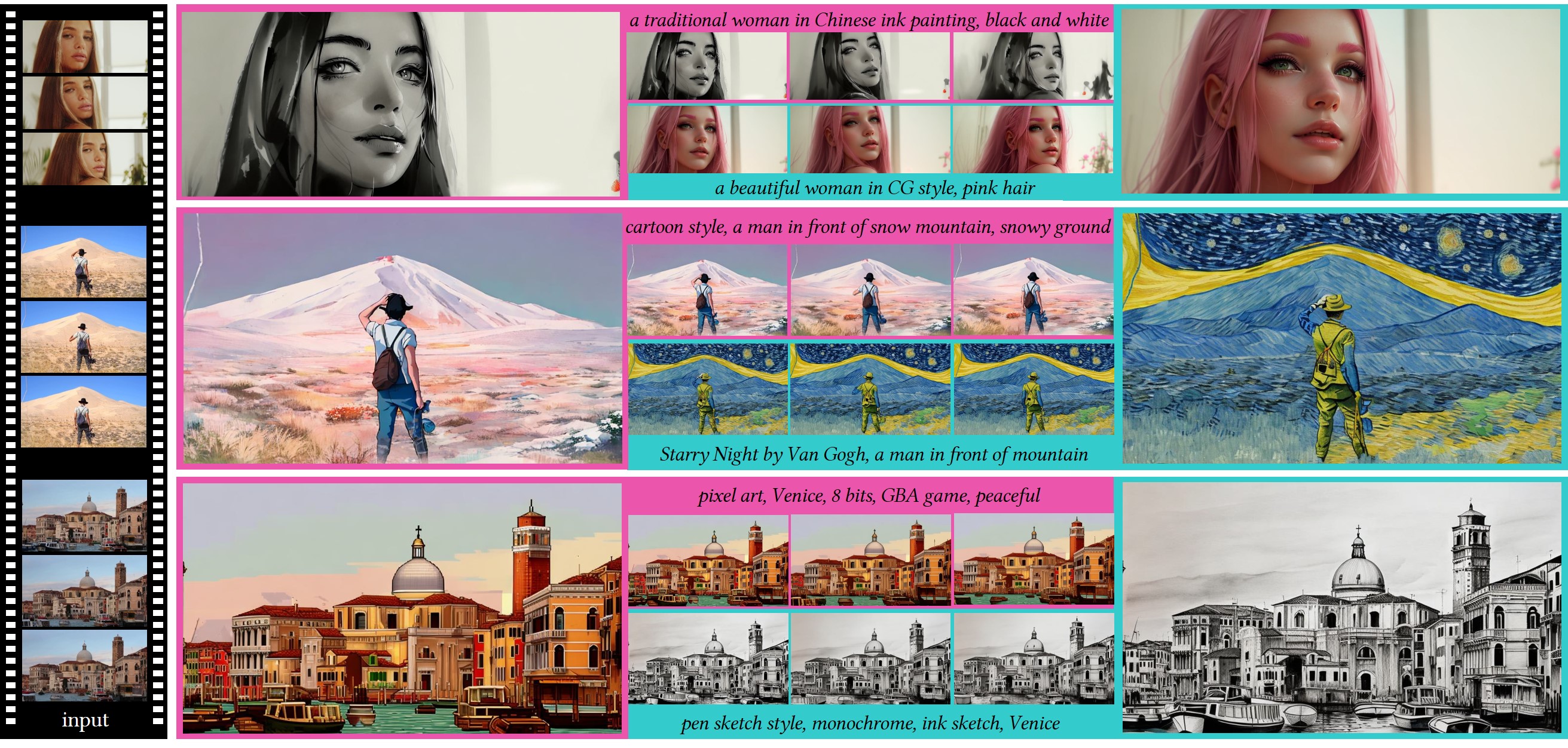 We present a novel zero-shot framework to adapt image diffusion models for text-guided video translation. Our method utilizes hierarchical cross-frame constraints to enforce temporal consistency in both global style and low-level textures, leveraging the key optical flow at a low cost (without re-training or optimization).
We present a novel zero-shot framework to adapt image diffusion models for text-guided video translation. Our method utilizes hierarchical cross-frame constraints to enforce temporal consistency in both global style and low-level textures, leveraging the key optical flow at a low cost (without re-training or optimization).

 We propose a versatile unsupervised image translation framework with generative prior that supports various translations from close domains to distant domains with drastic shape and appearance discrepancies.
We propose a versatile unsupervised image translation framework with generative prior that supports various translations from close domains to distant domains with drastic shape and appearance discrepancies.
 In the journal version, we condition GP-UNIT on a parameter to determine the intensity of the content correspondences during translation, allowing users to balance between content and style consistency for for close domains. For distant domains, we explore semi-supervised learning to guide GP-UNIT to discover accurate semantic correspondences that are hard to learn solely from the appearance.
In the journal version, we condition GP-UNIT on a parameter to determine the intensity of the content correspondences during translation, allowing users to balance between content and style consistency for for close domains. For distant domains, we explore semi-supervised learning to guide GP-UNIT to discover accurate semantic correspondences that are hard to learn solely from the appearance.

Other Projects

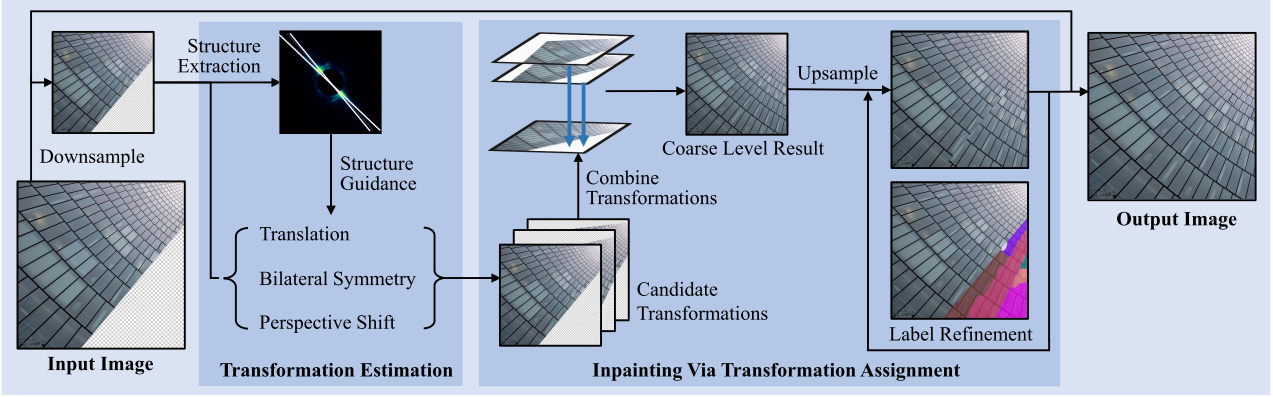 In this paper, we present a novel structure-guided framework for exemplar-based image inpainting. The main idea is to exploit the regularity of image self-similarity in forms of Homography transformation matrices to guide and improve the inpainting process.
In this paper, we present a novel structure-guided framework for exemplar-based image inpainting. The main idea is to exploit the regularity of image self-similarity in forms of Homography transformation matrices to guide and improve the inpainting process.
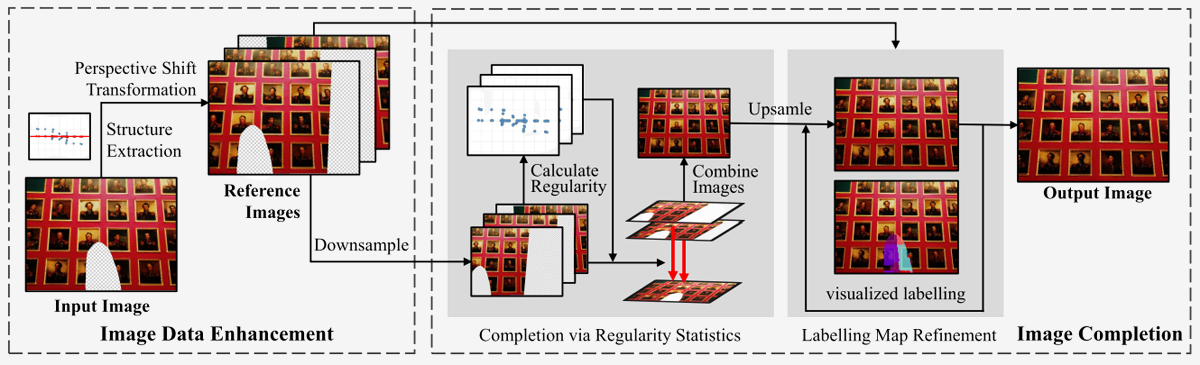 In this paper, we propose a novel hierarchical image completion approach using regularity statistics, considering structure features.
In this paper, we propose a novel hierarchical image completion approach using regularity statistics, considering structure features.
Course Projects
Logo Detection System
Digital Image Processing, 2016Shuai Yang, Yanghao Li and Yicheng Huang

Implemented SIFT-based and deep-based image detection algorithm.
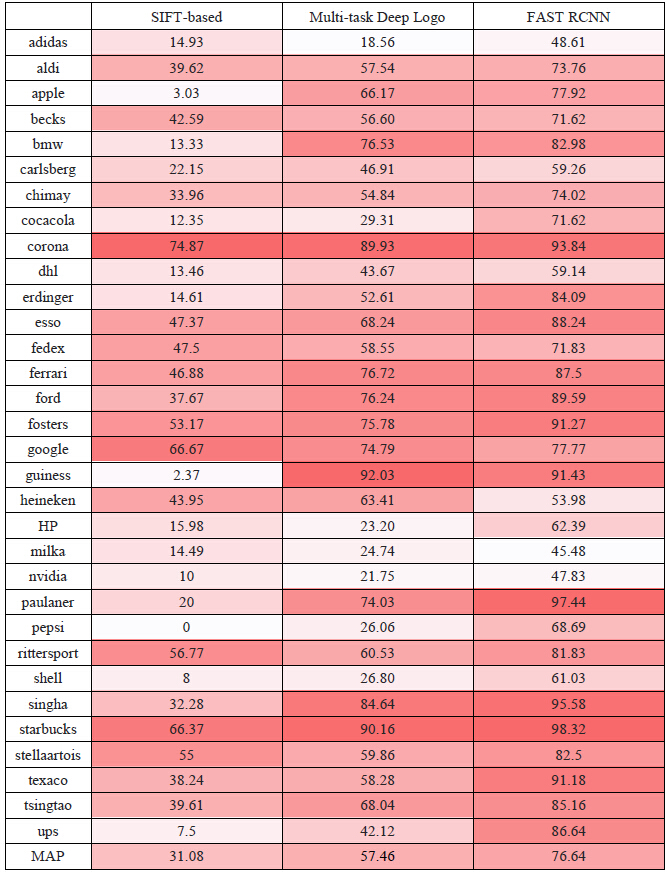
Simple Image Recognition System
Digital Image Processing, 2014Shuai Yang and Guangyuan Yang

Implemented the paper: Nister, David, Stewenius, Henrik. Scalable Recognition with a Vocabulary Tree. 2006:2161-2168.

Simple Video Processing System
Digital Video Processing and Analysis, 2014Shuai Yang, Li Meng and Chong Ruan

Implemented a video processing system that provides vide coding/decoding, stabilization and denoising functions.
e-Course
Computer Networks (Honor Track), 2014Shuai Yang, Yuan Huang, Gaoxiang Zhang and Ran Wang

e-Course is a mobile application helping Peking University students to select, comment and search courses. *I tried to make my PPT professional*

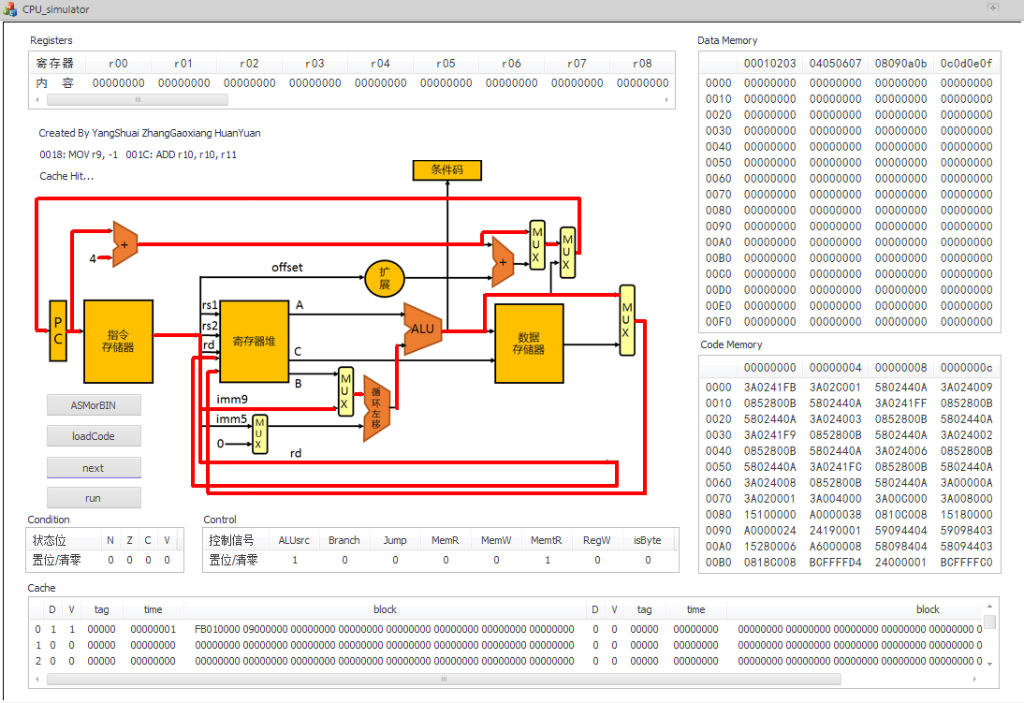
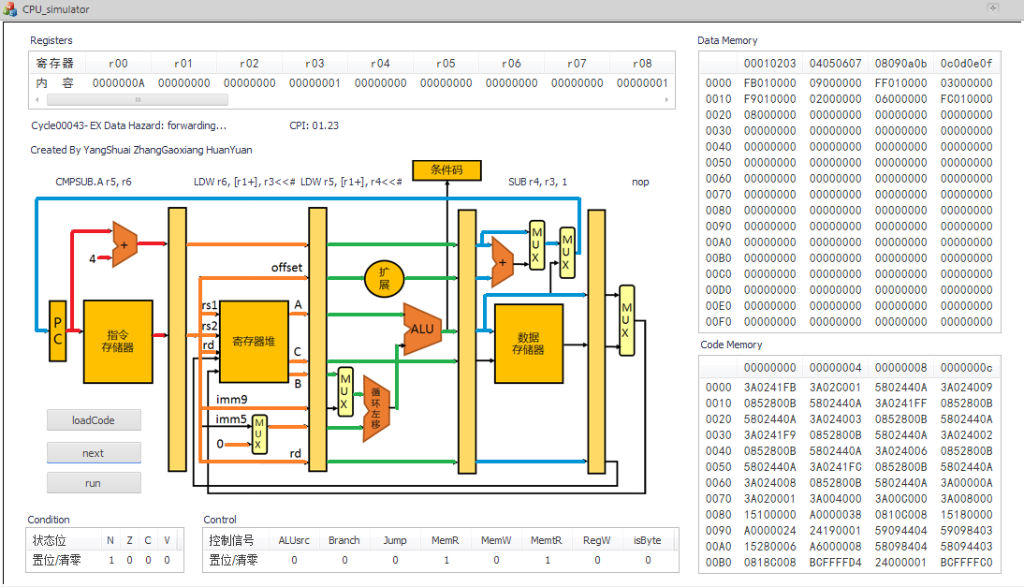
CPU Simulator
Computer Architectures, 2014Shuai Yang, Yuan Huang and Gaoxiang Zhang
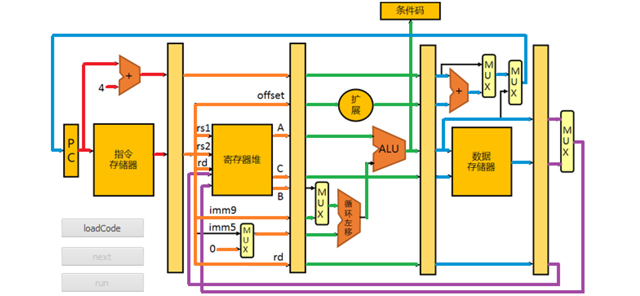
We learned MIPS and how CPU ran machine codes in pipeline this semester. We were asked to use C++ to simulate a CPU.
Taiko
Java Programming, 2013Shuai Yang, Yiming Wu, Yiqing Xue and Zheng Huang

Our team members like to play the music game OSU!. Therefore we developed our own Taiko.


LinkGame
Practice of Data Structure and Algorithm, 2012Shuai Yang, Yiming Wu and Yiqing Xue
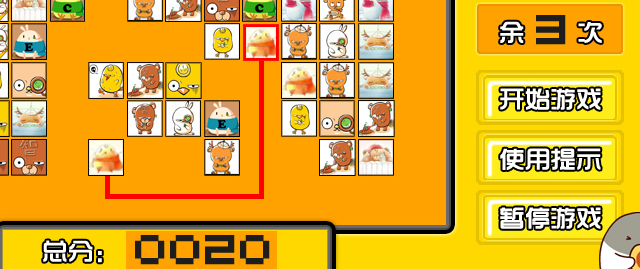
My first attempt at an MFC GUI. It's much more difficult than it looks :)

Leisure Gobang
Introduction to Computation, 2010Shuai Yang

It's really a challenge for me to come up with an AI smart enough to battle with human after only half a year's study of programming.