Towards Coding for Human and Machine Vision: Scalable Face Image Codin

Figure 1. We address image compression for joint human and machine vision in one framework. The proposed framework achieves high performance on both human and machine vision tasks under a tight constraint on the bit-rate.
Selected Results
Table 1. Quantitative comparison with JPEG and WEBP on both human vision task and machine vision task. We report classic SSIM, PSNR and deep-based perceptualL/perceptualH (perceptual loss [1] of conv2_2 layer and conv5_1 layer, respectively), LPIPS (Learned Perceptual Image Patch Similarity [2]), DISTS (Deep Image Structure and Texture Similarity [3]), FID (Fréchet Inception Distance [4]) for human vision task. We report NME (normalized point-to-point error for facial landmark detection), gender (gender classification accuracy), memorability (image memorability prediciton [5]) for machine vision task. We indicate for each metric whether higher (⇑) or lower (⇓) values are more desirable. Best scores are highlighted in bold.
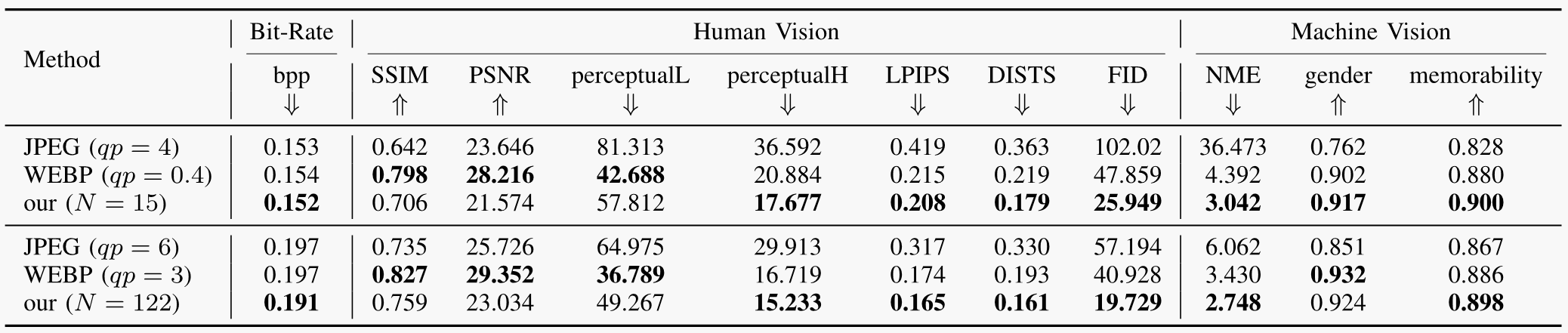
Human Vision: Visual Quality and Fidelity. In Figure 3, we present a visual comparison of the proposed method with JPEG compression under different quality parameters (qp), which are selected to matches the bit-rate of our method for fair comparison. It can be observed that JPEG compression yields distinct block artifacts, which greatly decrease visual quality. By comparison, our method produces more natural results. In Table 1, we report the SSIM, PSNR, perceptual loss, LPIPS, DISTS (for fidelity) and FID (for realism) between the reconstructed images and the ground truth. Our method outperforms JPEG compression in all metrics.







Figure 3. Visual comparison with JPEG compression. (a) Input image. (b)-(c) Images compressed by JPEG using quality parameter of 4, and 6, respectively. (d) Our decoded images using the encoded edge representations. (e)(f) Our decoded images using both the encoded edge representation and color representation under N=15 and N=122, respectively. For each reconstructed image, its bit-rate (bit per pixel, bpp) is shown in the lower left black box.
Machine Vision: Landmark Detection and Gender Classification. The machine vision performance is tested on the high-level facial landmark detection and gender classification tasks. We perform facial landmark detection [6] and gender classification [7] on the original VGGFace2 dataset [8] and the reconstructed dataset by JPEG and our method. Results on the original data are served as ground truth. Figure 4 visualizes the results. In Table 1, we report the normalized point-to-point error (NME) between the detection results on the compressed data and the ground truth, the gender classification accuracy and predicted image memorability [5]. Our method outperforms JPEG compression in the two tasks.



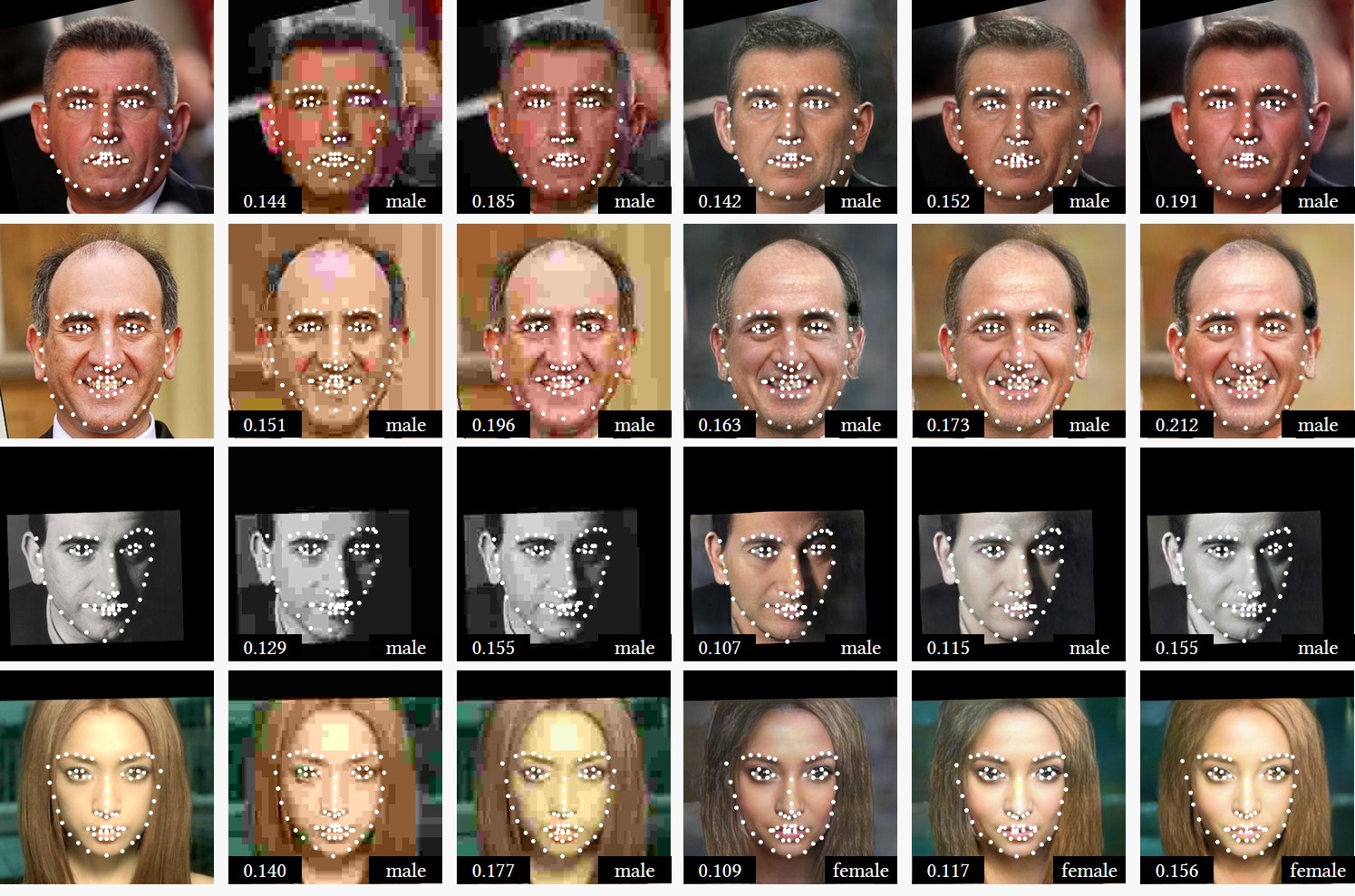



Figure 4. Comparison with JPEG compression on landmark detection and gender classification. (a) Input image. (b)-(c) Results by JPEG using quality parameter of 4, and 6, respectively. (d) Our results using the encoded edge representations. (e)(f) Our results using both the encoded edge representation and color representation under N=15 and N=122, respectively. For each reconstructed image, its bit-rate (bit per pixel, bpp) is shown in the lower left black box, its classified gender is shown in the lower right black box. The detected landmarks are shown as white circles.
Reference
[1] J. Johnson, A. Alahi, and F. F. Li. Perceptual losses for real-time style transfer and super-resolution. ECCV 2016.
[2] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. CVPR 2018.
[3] K. Ding, K. Ma, S. Wang, and E. P. Simoncelli. Image quality assessment: Unifying structure and texture similarity. Available: https://arxiv.org/abs/2004.07728
[4] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. GANS trained by a two time-scale update rule converge to a local nash equilibrium. NIPS 2017.
[5] A. Khosla, A. S. Raju, A. Torralba, and A. Oliva. Understanding and predicting image memorability at a large scale. ICCV 2015.
[6] A. Bulat and G. Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). ICCV, 2017.
[7] S. I. Serengil and A. Ozpinar, Lightface: A hybrid deep face recognition framework. IEEE INISTA, 2020.
[8] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman, Vggface2: A dataset for recognising faces across pose and age. IEEE FG 2018.