Towards Coding for Human and Machine Vision: A Scalable Image Coding Approach

Figure 1. Visual comparison with JPEG compression. (a) Input image. (b)-(d) Images compressed by JPEG using quality parameter of 4, 7 and 8, respectively. (e) Our decoded images using the encoded edge representations. (f) Our decoded images using both the encoded edge representation and color representation. For each reconstructed image, its bit-rate (bit per pixel, bpp) is shown in the lower left black box.
Abstract
The past decades have witnessed the rapid development of image and video coding techniques in the era of big data. However, the signal fidelity-driven coding pipeline design limits the capability of the existing image/video coding frameworks to fulfill the needs of both machine and human vision. In this paper, we come up with a novel image coding framework by leveraging both the compressive and the generative models, to support machine vision and human perception tasks jointly. Given an input image, the feature analysis is first applied, and then the generative model is employed to perform image reconstruction with features and additional reference pixels, in which compact edge maps are extracted in this work to connect both kinds of vision in a scalable way. The compact edge map serves as the basic layer for machine vision tasks, and the reference pixels act as a sort of enhanced layer to guarantee signal fidelity for human vision. By introducing advanced generative models, we train a flexible network to reconstruct images from compact feature representations and the reference pixels. Experimental results demonstrate the superiority of our framework in both human visual quality and facial landmark detection, which provide useful evidence on the emerging standardization efforts on MPEG VCM (Video Coding for Machine).
Framework
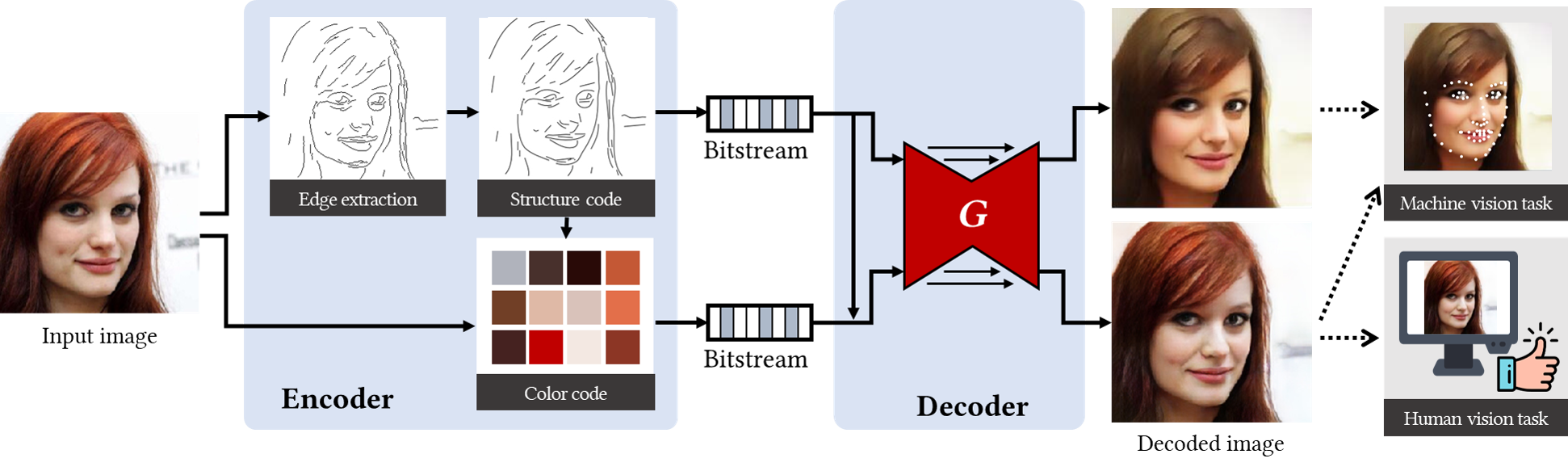
Figure 2. Overview of the proposed vision-driven image coding framework.
Selected Results
Human Vision: Visual Quality Evaluation. In Figure 1, we present a visual comparison of the proposed method with JPEG compression under different quality parameters (qp), which are selected to matches the bit-rate of our method for fair comparison. It can be observed that JPEG compression yields distinct block artifacts, which greatly decrease visual quality. By comparison, our method produces more natural results.
Machine Vision: Landmark Detection. The machine vision performance is tested on the high-level facial landmark detection task. We perform facial landmark detection on the original VGGFace2 dataset [1] and the reconstructed dataset by JPEG and our method. Detection results on the original data are served as ground truth. We then calculate the normalized point-to-point error (NME) between the detection results on the compressed data and the ground truth. Figure 3 illustrates the averaged NME and the bit-rate of JPEG compression and our method. It can be clearly seen that our method achieves much fewer errors at the similar bit-rate compared to JPEG. Figure 4 further shows the cumulative error distribution, where more than 90% of the images reconstructed by the proposed method have tiny errors less than 5%, showing great robustness.
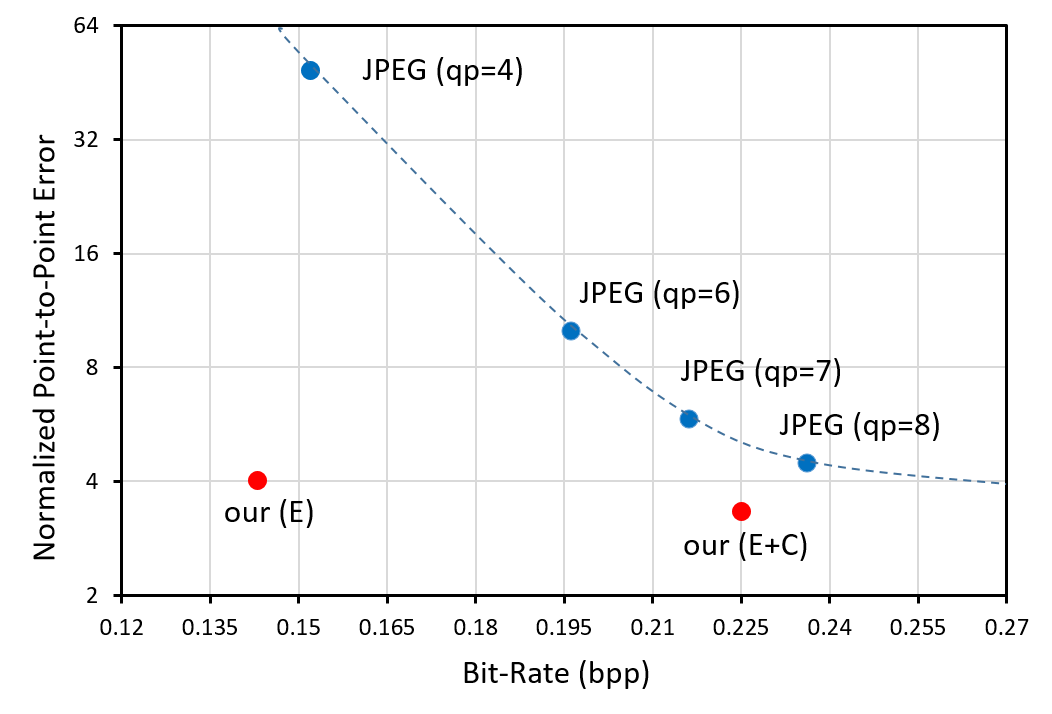
Figure 3. Illustration of the averaged normalized point-to-point error (NME) on facial landmark detection and bit-rate of JPEG compression and the proposed method.
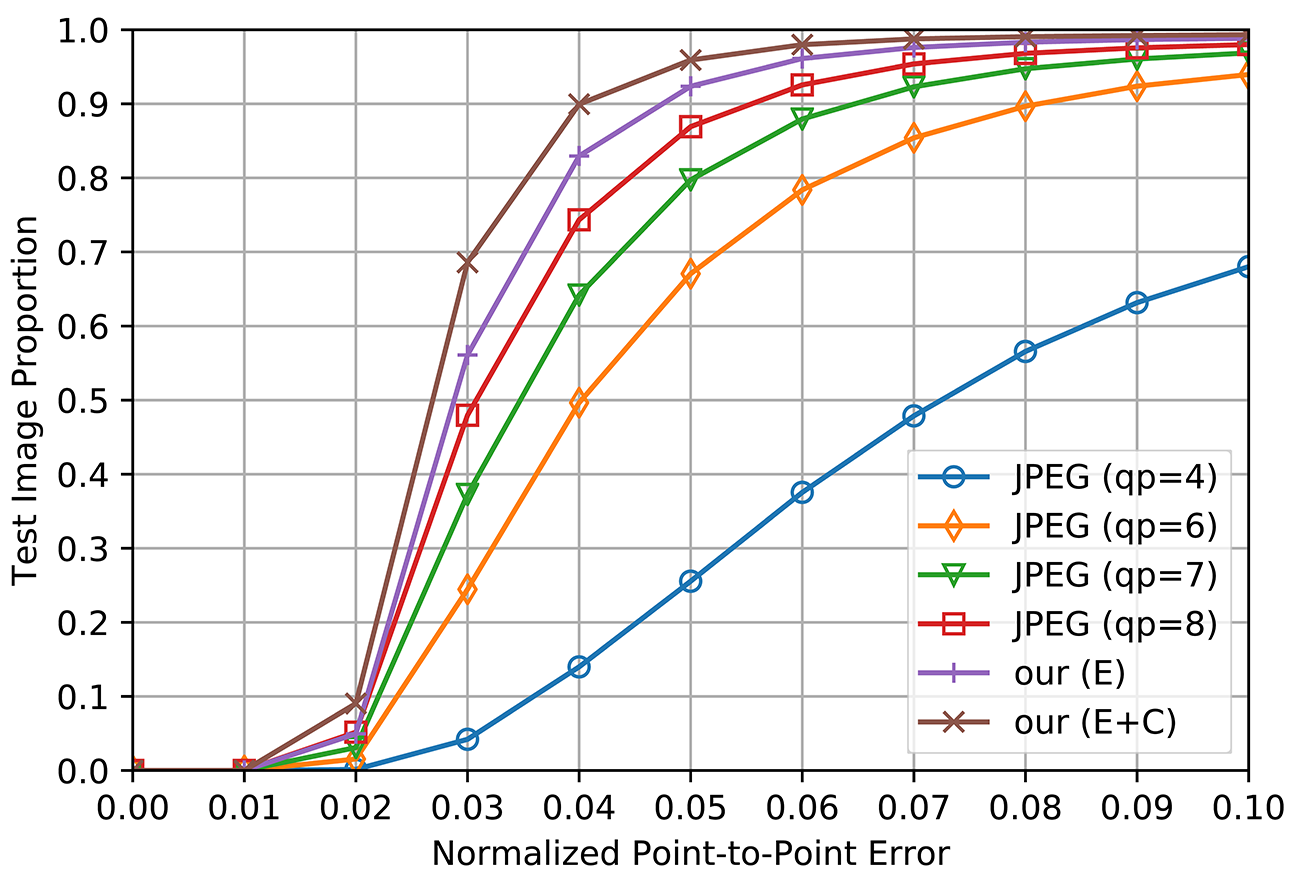
Figure 4. Cumulative error distribution of JPEG compression and the proposed method on facial landmark detection.
Reference
[1] A. Bulat and G. Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). ICCV, 2017.