Deep Plastic Surgery: Robust and Controllable
Image Editing with Human-Drawn Sketches
 |
 |
 |
 |
 |
 |
| (a) controllable face synthesis | (b) controllable face editing |
 |
| (c) adjusting refinement level l |
Figure 1. Our Deep Plastic Surgery framework allows users to (a) synthesize and (b) edit photos based on hand-drawn sketches. (c) Our model works robustly on various sketches by setting refinement level l adaptive to the quality of the input sketches, i.e., higher l for poorer sketches, thus tolerating the drawing errors and achieving the controllability on sketch faithfulness. Note that our model requires no real sketches for training.
Abstract
Sketch-based image editing aims to synthesize and modify photos based on the structural information provided by the human-drawn sketches. Since sketches are difficult to collect, previous methods mainly use edge maps instead of sketches to train models (referred to as edge-based models). However, sketches display great structural discrepancy with edge maps, thus failing edge-based models. Moreover, sketches often demonstrate huge variety among different users, demanding even higher generalizability and robustness for the editing model to work. In this paper, we propose Deep Plastic Surgery, a novel, robust and controllable image editing framework that allows users to interactively edit images using hand-drawn sketch inputs. We present a sketch refinement strategy, as inspired by the coarse-to-fine drawing process of the artists, which we show can help our model well adapt to casual and varied sketches without the need for real sketch training data. Our model further provides a refinement level control parameter that enables users to flexibly define how ``reliable'' the input sketch should be considered for the final output, balancing between sketch faithfulness and output verisimilitude (as the two goals might contradict if the input sketch is drawn poorly). To achieve the multi-level refinement, we introduce a style-based module for level conditioning, which allows adaptive feature representations for different levels in a singe network. Extensive experimental results demonstrate the superiority of our approach in improving the visual quality and user controllablity of image editing over the state-of-the-art methods.
Framework
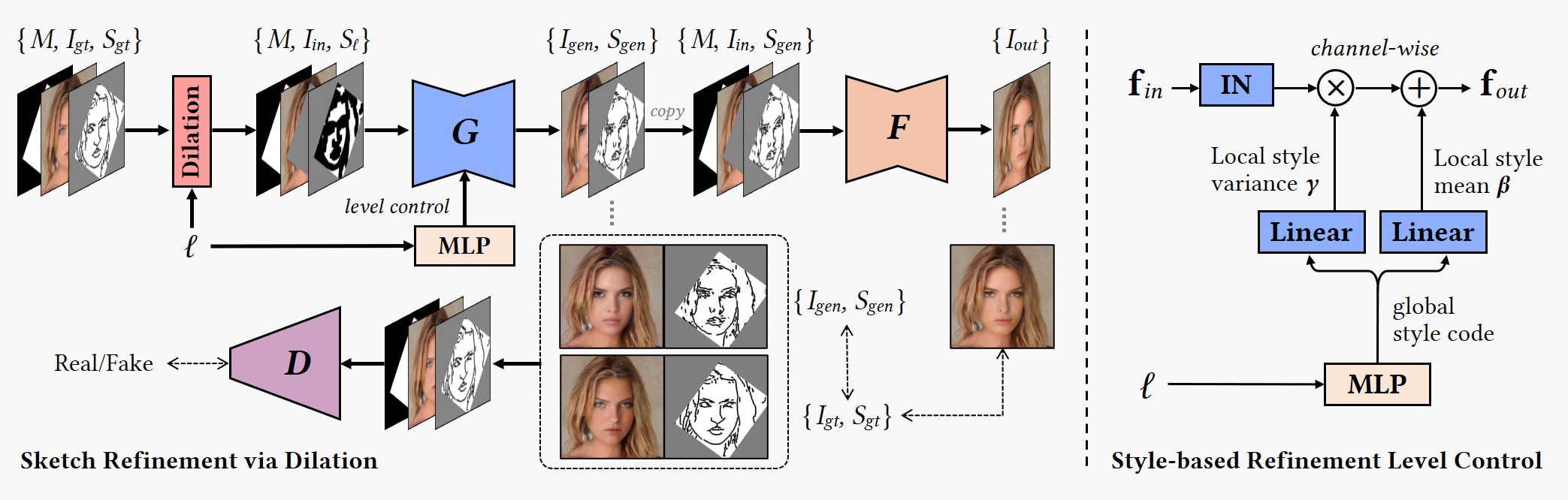
Figure 2. Framework overview. A novel sketch refinement network G is proposed to refine the rough sketch Sl modelled as dilated drawable regions to match the fine edges Sgt. The refined output Sgen is fed into a pretrained edge-based model F to obtain the final editing result Iout. A parameter l is introduced to control the refinement level. It is realized by encoding l into style codes and performing a style-based adjustment over the outputs fin of the convolutional layers of G to remove the dilation-based styles.
Resources
Citation
@inproceedings{Yang2020Deep, title={Deep Plastic Surgery: Robust and Controllable Image Editing with Human-Drawn Sketches}, author={Yang, Shuai and Wang, Zhangyang and Liu, Jiaying and Guo, Zongming}, booktitle={European Conference on Computer Vision}, year={2020} }
Selected Results

Figure 3. Comparison with state-of-the-art methods on face edting. (a) Input photos, masks and sketches. (b) DeepFillv2 [1]. (c) SC-FEGAN [2]. (d) Our results with l=0. (e) Our results with l=1. (f) SC-FEGAN using our refined sketches as input.

Figure 4. Comparison with state-of-the-art methods on face synthesis. (a) Input human-drawn sketches. (b) BicycleGAN [3]. (c) pix2pixHD [4]. (d) pix2pix [5]. (e) Our results with l=1. (f) pix2pixHD using our refined sketches as input.
Reference
[1] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, T.S. Huang. Free-form image inpainting with gated convolution. ICCV 2019.
[2] Y. Jo, J. Park. SC-FEGAN: Face editing generative adversarial network with user’s sketch and color. ICCV 2019.
[3] J.Y. Zhu, R. Zhang, D. Pathak, T. Darrell, A.A. Efros, O. Wang, E. Shechtman. Toward multimodal image-to-image translation. NeurIPS 2017.
[4] T.C. Wang, M.Y. Liu, J.Y. Zhu, A. Tao, J. Kautz, B. Catanzaro. High-resolution image synthesis and semantic manipulation with conditional GANs. CVPR 2018.
[5] P. Isola, J.Y. Zhu, T. Zhou, A.A. Efros. Image-to-image translation with conditional adversarial networks. CVPR 2017.